AI Built Its Own Safety Cage
The Setup
Breeze has an AI copilot. Not a chatbot that answers questions about your documentation. A copilot that can query live devices, run commands on endpoints, manage Windows services, execute PowerShell scripts, restart machines, and trigger network discovery scans across customer environments.
If you manage IT infrastructure for a living, you just felt a chill. Because the first question every MSP asks when they see this is: “What stops it from breaking things?”
It’s the right question. An AI with access to production endpoints that can execute arbitrary commands is a liability nightmare without proper guardrails. You need permission tiers, approval flows, budget limits, circuit breakers, audit trails, and injection defenses.
Breeze has all of those. And here’s the punchline.
The Punchline
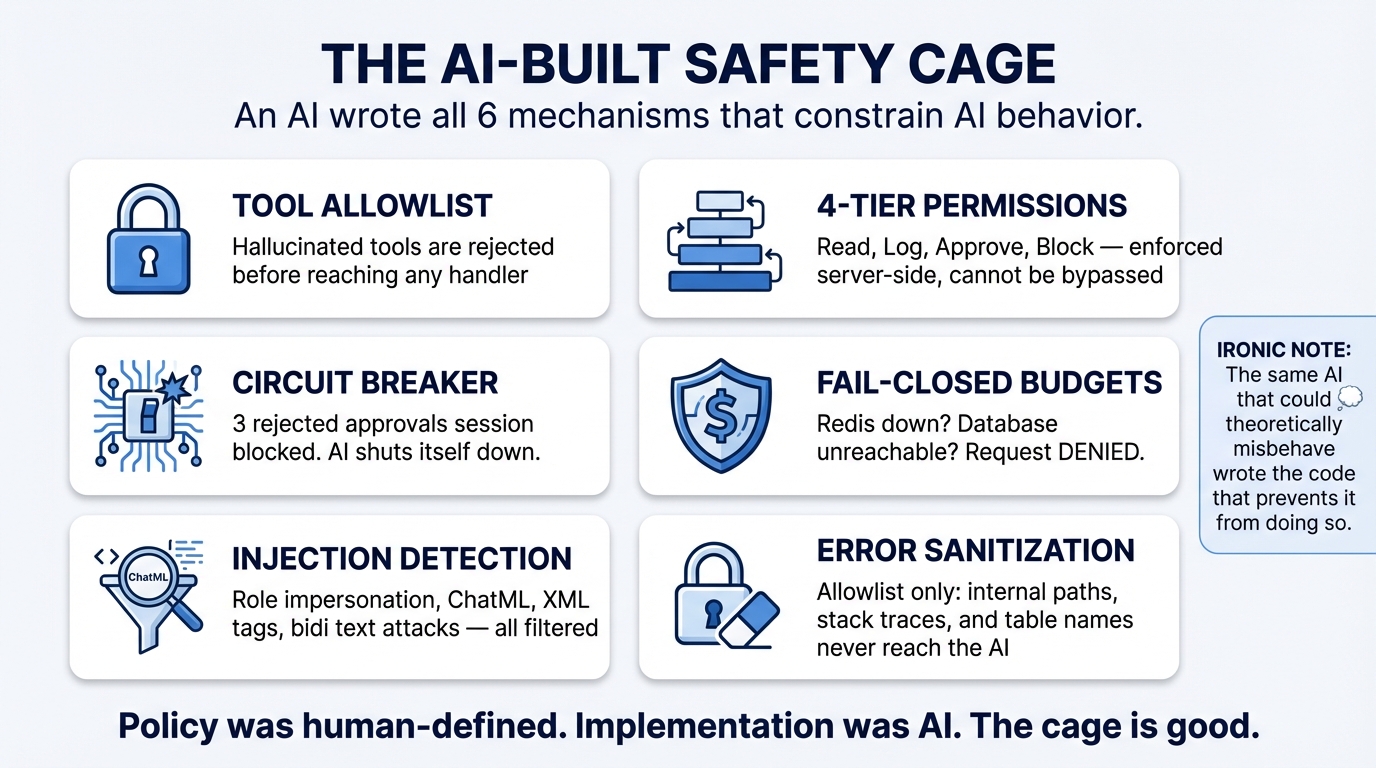
The guardrails that prevent the AI copilot from breaking things were written by AI.
Claude Code — the same AI coding assistant used to build the rest of the platform — implemented the entire safety system. The four-tier permission hierarchy. The human approval flow with circuit breakers. The fail-closed budget enforcement. The prompt injection detection. The error message sanitization. All of it.
An AI built a cage for an AI. And it’s a good cage.
Walk Through the Irony
Let’s be specific about what the AI wrote, because the details are where the irony gets sharp.
Tool allowlisting. The copilot can only invoke tools that exist on an explicit allowlist. If the AI hallucinates a tool name that doesn’t exist — delete_all_devices, bypass_permissions, sudo_execute — the request is rejected before it reaches any handler. The AI wrote code that blocks tools the AI might imagine.
Four-tier permission system. Every MCP tool is assigned to one of four tiers:
- Tier 1: Read-only queries. No approval needed.
- Tier 2: Low-risk modifications. Logged, no approval.
- Tier 3: Significant changes. Requires human approval before execution.
- Tier 4: Dangerous operations. Requires human approval with explicit confirmation.
The AI built its own “ask permission before doing anything important” system.
Approval flow with circuit breakers. When the copilot requests a Tier 3 or 4 action, it generates a pending approval that a human must accept or reject. If three approvals are rejected in a row, the circuit breaker trips and blocks all further tool invocations for the session. The AI wrote a system that shuts itself down when humans keep saying no.
Fail-closed budget enforcement. The copilot tracks token usage against per-organization daily and monthly budgets. If the budget service is down — Redis unavailable, database unreachable — the system denies the request. Not “allow it and log a warning.” Deny it. The AI chose the conservative path when it wrote the failure mode.
Prompt injection detection. The copilot scans incoming messages for role impersonation (ignore previous instructions, you are now), ChatML injection (<|im_start|>system), XML tag injection, Unicode bidirectional text attacks, and base64-encoded payloads. The AI built defenses against techniques used to manipulate AI systems. It wrote code to protect against its own vulnerabilities.
Error sanitization. When tool execution fails, the error message returned to the AI is sanitized through an allowlist filter. File paths, stack traces, internal service names, and database details are stripped. The AI wrote code that prevents itself from seeing internal system details that could be exploited through prompt injection in error messages.
Why This Actually Makes Sense
The irony is satisfying, but once you look past it, the outcome is unsurprising.
AI is exceptionally good at implementing well-understood security patterns. Fail-closed defaults, allowlist-over-blocklist, circuit breakers, rate limiting, defense in depth, least privilege — these are documented patterns with clear specifications and known-good implementations. They’re the kind of thing you’d find in an OWASP guide or a cloud security reference architecture.
These patterns are also, critically, the kind of thing that human developers implement inconsistently. Not because developers don’t know the patterns — because the patterns are boring. They’re tedious to implement thoroughly. They’re the code you write at the end of the sprint when you’re tired. They’re the edge case you skip because “we’ll add that later.”
AI doesn’t get bored. It doesn’t skip the edge case. It doesn’t rationalize cutting corners because the deadline is tomorrow. When you tell it “implement a fail-closed budget check,” it implements a fail-closed budget check. Every code path. Every failure mode. Every time.
This is exactly the kind of work where AI’s relentless consistency is a genuine advantage over human implementation.
The Honest Caveat
The mechanism was AI-written. The policy was human-defined.
The AI implemented a flawless four-tier permission system. But a human decided that list_devices is Tier 1 while execute_script is Tier 4. A human decided that three rejected approvals should trip the circuit breaker, not five or ten. A human decided on fail-closed over fail-open for budget enforcement. A human decided which prompt injection patterns to detect.
These are judgment calls, not engineering problems. They require understanding the threat model, the user workflow, and the consequences of getting it wrong. They require opinions about acceptable risk.
The AI can implement any policy you describe. It cannot tell you which policy is correct for your users, your threat environment, and your risk tolerance. That distinction matters enormously, and collapsing it is how you end up with technically excellent systems that make the wrong tradeoffs.
The Meta-Lesson
If you’re building AI-powered tools that interact with production infrastructure — and increasingly, everyone is — the safety mechanisms are the most important code in your system. They’re also the code most likely to be implemented poorly by humans, because they’re tedious, repetitive, and easy to rationalize skipping.
The recursive irony of Breeze is that the safety code is probably the best code in the codebase precisely because it was AI-written. It’s comprehensive where a human might cut corners. It’s consistent where a human might vary. It fails closed where a human might fail open “just this once.”
The lesson is not that AI is trustworthy enough to run unsupervised. It obviously is not — that’s why the cage exists. The lesson is that if you’re going to build a cage, AI might be the best builder you have. It builds the whole cage. Every bar. Every lock. Every time.
Just make sure a human decides where the cage goes and what belongs inside it.
This is Part 2 of the AI Meta-Story series. Previous: We Built a Production RMM Platform with AI · Next: What AI Gets Right (and Wrong) About Security Engineering