Why We Built Our Own RMM
When we started building LanternOps, the plan was not to write an RMM. The plan was to build an AI brain that sat on top of whatever RMM an MSP already used, made it smarter, and automated the tedious parts of running a managed service business. We evaluated every major platform on the market. By the end, we had ruled all of them out as a foundation — not because they were bad products, but because they were built for a fundamentally different consumer than the one we were designing for.
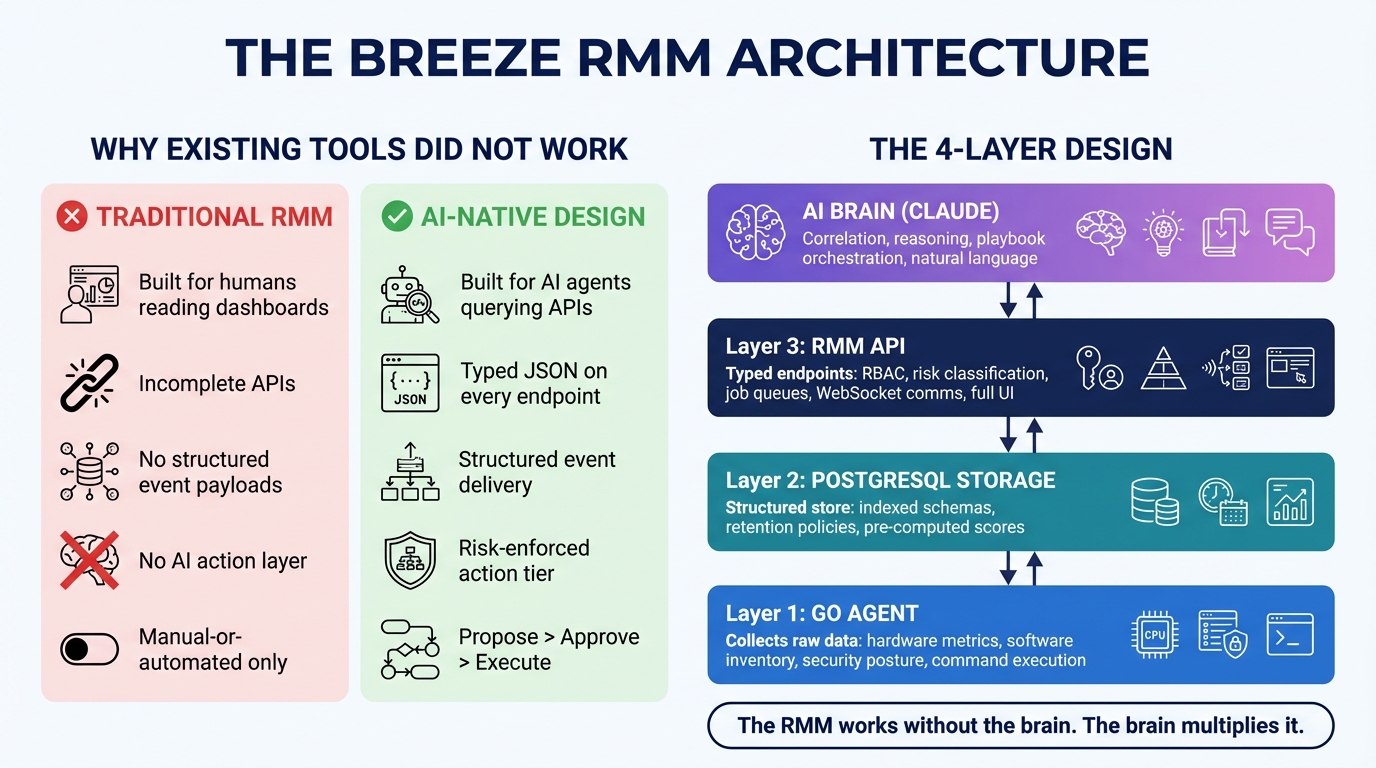
They were built for human technicians reading dashboards. We needed something built for an AI agent querying structured APIs.
That distinction sounds narrow. It is not. It touches everything: how data is modeled, how events are emitted, how actions are classified, how the API is shaped. An RMM built for human consumption and an RMM built for agent consumption are different products, even if they do the same surface-level things.
What an AI Brain Actually Needs From Its Data Layer
Before getting into what we found, it is worth being precise about what the brain actually requires.
An AI agent needs four things from the RMM underneath it:
Structured, queryable data. The brain reasons by calling tools — get_device_details, get_alerts, get_patch_status. Each of those tools wraps an API call. That API call needs to return typed, normalized data the agent can work with directly. Not HTML. Not a PDF report. Not a dashboard screenshot. Typed JSON that the agent can reason over without parsing or interpretation.
Pre-computed state. The brain should not have to compute things that can be computed once and stored. If you want to know a device’s reliability score, the right answer is a scheduled job that runs every hour, stores the result in PostgreSQL, and exposes it via a 50-millisecond API call. The wrong answer is asking the agent to reason over raw crash logs every time reliability comes up — which costs tokens, takes seconds, and produces inconsistent results across sessions.
A risk-enforced action layer. An AI that can take actions is only useful if there is a principled way to classify which actions are safe to take autonomously and which require human approval. This cannot be left to the brain’s judgment. It has to be enforced at the platform level, below where the brain operates, in a way the brain cannot override or bypass.
Real-time event delivery. The brain should not poll. The RMM should push events when things happen — a disk crosses a threshold, a patch fails, a login brute force is detected. Events need a consistent envelope: type, severity, category, affected devices, structured payload. The brain subscribes, triages, and acts.
What We Actually Found
We evaluated the major RMM platforms with a specific lens: can we build an AI brain on this, or are we fighting it the whole way?
The data access situation was the first red flag. Several platforms had data primarily accessible through their UI, with API coverage that was meaningful but incomplete — enough for building integrations, but not enough for an agent that needs to query everything. In some cases, scraping was genuinely the only path to certain data. That is not a foundation for an AI product.
The event models were inconsistent. Alert systems were designed for humans to triage, not agents to act on. Alerts might have a severity and a device ID and a text description — but not a typed, structured payload. Writing code against that data requires building an interpreter between the raw event and the agent. That interpreter becomes a maintenance burden and a reliability risk.
The more fundamental issue was the action model. Every RMM we looked at had two modes: a human manually clicks something in the UI, or a rule fires automatically. There was no concept of a third category — an AI that proposes an action with a stated reason, which a human approves or denies, and which gets executed with a full audit trail either way. The space between “fully manual” and “automated rule” was empty.
That empty space is exactly where an AI agent lives.
An AI agent is not a rule. A rule says: if CPU > 95% for 5 minutes, send an alert. An AI agent says: CPU has been elevated on this machine for 3 days, it correlates with a background indexing job that started after last week’s Office update, the machine’s owner is the VP of Sales who has a board presentation tomorrow, and I recommend waiting until after 6 PM to restart the service rather than doing it now. That is reasoning, not a rule. And the platform underneath it needs to be built for reasoning.
Why the Architecture Had to Be Four Layers
When we decided to build Breeze instead of adapting an existing RMM, we made one core architectural commitment: the brain would be a first-class consumer from day one, not a retrofit.
That commitment produced a four-layer design:
Agent (Go, running on endpoints) — collects raw data. Hardware metrics, software inventory, SMART drive data, boot performance, change diffs, security posture, active sessions, event logs. The agent is a data collector and command executor. It has no opinions about what the data means.
Storage (PostgreSQL) — persists everything the agent collects, with the right indexes, retention policies, and schema for the queries that will run against it. This is not a log sink. It is a structured store designed for the API layer to serve efficiently.
RMM API (Hono/TypeScript) — exposes the stored data through typed endpoints, runs scheduled computation jobs (reliability scores, anomaly detection, compliance checks, NVD vulnerability correlation), and enforces the risk classification layer on every action. This layer is fully useful without the brain. An MSP can run dashboards, configure alerts, manage patches, and run scripts entirely through the API and UI. The brain makes it smarter; it is not required for basic function.
Brain (Claude Agent SDK) — calls the API through typed tools. It does correlation, decision-making, playbook orchestration, and natural language reasoning. Crucially, it does not compute things the API layer can compute more cheaply. And it cannot take actions that the API layer has classified as requiring human approval.
The risk enforcement point bears repeating. Risk classification is not a brain-level concern. The brain should not be self-regulating on this — that creates a category error where safety depends on the AI being well-behaved. Instead, every action the brain can call has a tier: read-only (auto-execute), mutating with notification, mutating with approval required, or always blocked from autonomous execution. Those tiers are enforced at the API layer, evaluated before execution, regardless of what the brain requested or why.
The Anti-Patterns We Designed Against
The wrong way to build this is to start with the brain and work downward. We have seen this pattern described as an approach: give the agent a script execution tool and let it gather whatever data it needs on demand.
The problems are concrete. If the brain runs smartctl every time it needs SMART data, every query costs AI tokens and takes seconds. There is no historical data, because you only collected it when you asked. There are no dashboards, because the data was never stored. There are no alerts, because detection requires persistent monitoring, not on-demand queries. The system breaks when the brain is unavailable or over budget, which means the underlying monitoring breaks too.
The correct pattern: the agent collects SMART data on a scheduled interval. The API stores it and computes a health score. The dashboard shows that score. Alert rules fire when the score drops below a threshold. The brain calls get_device_hardware_health and gets a structured response it can reason about in under 100 milliseconds, at zero token cost, with historical trend data included.
The distinction between what lives in the brain and what lives in the RMM comes down to a simple test: would this be useful without the brain running? A reliability score is useful without the brain — it shows up on a dashboard, drives alert rules, appears in reports. A cross-signal correlation (“this reliability drop correlates with the driver update that deployed 48 hours ago”) requires reasoning and belongs in the brain.
Security functions belong in the RMM. Audit baseline configuration, compliance checks, event logging — these should not depend on AI availability. Core security posture cannot have a single point of failure. Compliance state should live in PostgreSQL, queryable and auditable, not in the brain’s session memory where it evaporates between conversations.
CIS Controls v8 as a Test of the Architecture
We used CIS Controls v8 as a calibration target during design. Of the 18 controls, Breeze currently covers 13 at what the framework calls “Strong” implementation through its 32 Brain Enablement features.
That number is higher than most RMMs achieve because the data pipelines were designed for it from the start. CIS Controls are not a checklist you retrofit. They require continuous data collection, automated comparison against baselines, real-time compliance state, and the ability to act on findings. When the collection layer, storage layer, and computation layer are purpose-built for AI consumption, adding a compliance evaluation tool to the brain’s toolkit is a thin wrapper around data that already exists. When they are not, you are building backward.
The 32 Brain Enablement features each have a defined split between what the agent collects, what the API computes, and what the brain reasons about. Four of those features — device context memory, self-healing playbooks, end-user diagnostic chat, and incident response orchestration — live purely in the brain and require no new agent or API code. Everything else has an RMM implementation that is fully functional without the brain. You could remove the brain tomorrow and the monitoring, alerting, patching, and dashboards would all continue working.
That is the design invariant: the RMM is a complete product. The brain is multiplicative on top of it, not load-bearing.
The Honest Admission
Building your own RMM is not the obvious choice. It is a significant undertaking. There are established players with years of development, large agent install bases, and deep PSA integrations. The question we had to answer honestly was: is adapting an existing RMM to serve AI consumption actually tractable, or would we spend years fighting the architecture instead of building the product?
We concluded we would be fighting. The data access gaps, the event model limitations, the missing risk layer — these are not bugs you file a ticket about. They are fundamental to how the products were designed. They were designed for a world where every action flows through a human decision point. Retrofitting a first-class autonomous action layer onto that design is a multi-year project against a codebase you do not control.
Building Breeze took longer upfront. We will not pretend otherwise. But the foundation is right — and in systems software, the foundation determines what is possible later.
The brain connector architecture means the same tool definitions work for both BYOK mode (a user’s own Anthropic API key, running locally, calling the RMM API directly) and LanternOps (our commercial cloud brain, running multi-agent orchestration with persistent cross-tenant memory). The API endpoints, risk enforcement, and tool schemas are identical. The only difference is auth and network path. That portability is only possible because both modes were first-class requirements from the beginning, not added later.
This post is the first in a series on how we built Breeze and what we learned. The next posts go deeper on specific pieces of the architecture — the risk classification system, the brain connector interface, the specific data pipelines behind each CIS control coverage point. If you are building something in this space, or thinking about it, we hope the specifics are useful.
Breeze RMM is open source. LanternOps is the commercial brain built on top of it. The code is at github.com/breezermm/breeze.