Risk Tiers for Autonomous Action: How to Let AI Act Without Breaking Production
The hardest design problem in autonomous AI systems is not “how do I make the AI smarter?” It is “how do I let the AI act on 80% of cases without supervision while ensuring the other 20% get appropriate human review?”
Most teams who ship AI into production discover this the hard way. They start with a conservative implementation — read-only access, everything surfaced as a recommendation, humans act on all of it. The AI is safe. It is also nearly useless, because the operational value of autonomous action is exactly what the read-only constraint eliminates. Then they loosen the constraint. The AI starts acting. Something goes wrong — a reboot during business hours, a patch applied outside the maintenance window, a script run against the wrong device scope. They tighten the constraint. They are back where they started.
The problem with this oscillation is that it treats the question as binary: either the AI has autonomy or it does not. The architectural answer is that autonomy is not binary. It is a function of risk, and risk classification is an engineering problem that has a tractable solution.
The Four Tiers
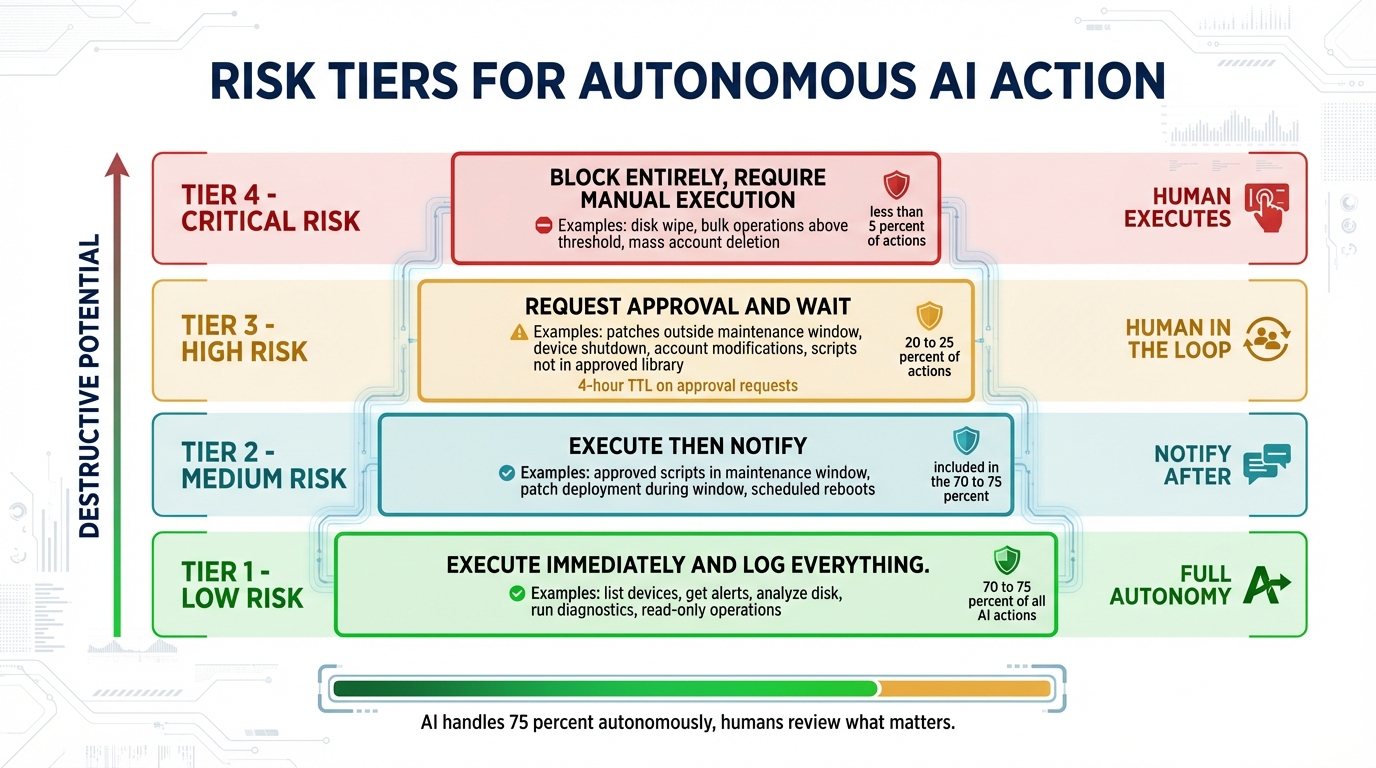
Risk classification in Breeze’s Brain Connector API divides every possible action into four tiers. The tiers are not arbitrary — they are derived from two underlying questions: what is the destructive potential of this action if it goes wrong, and how reversible is the outcome?
Low Risk: Execute Immediately, Log Everything
Low-risk actions have zero destructive potential. This covers all read operations — list_devices, get_alerts, search_logs, get_hardware_health, get_security_posture — and safe diagnostic operations like run_network_diagnostics, analyze_disk_usage, and analyze_boot_performance. Nothing changes. Nothing breaks. The AI can run these freely and continuously.
The only requirement is logging. Every Low-tier execution is written to the audit trail. Not for safety reasons — these actions cannot cause harm — but because audit completeness matters for compliance, and because the log of what the AI was examining is often useful context when reviewing a High-tier approval request that followed.
Medium Risk: Execute, Then Notify
Medium-risk actions are guarded mutations: approved scripts running against their designated device scope, patches deploying within an active maintenance window, reboots scheduled during a maintenance window, DNS configuration changes, minor startup item management. These are operations where the expected outcome is known, the timing is appropriate, and the potential for harm is low enough that post-hoc review is sufficient.
The rule for Medium is: execute immediately, notify immediately. The relevant tech receives a notification — via Slack, email, or dashboard, per org configuration — that describes what the brain did and why. The tech reviews after the fact and flags anything that looks wrong.
The reason this tier exists rather than collapsing everything into approval workflows is timing. A maintenance window is typically two to four hours. If every action within that window requires individual pre-approval, the window is consumed by approval latency rather than remediation work. The value of the maintenance window — a defined, low-risk period to make changes — is entirely lost. Medium risk acknowledges that some actions are appropriate to execute autonomously precisely because the operational context already contains the approval signal.
High Risk: Request Approval, Wait
High-risk actions are state-changing operations outside their normal context: patches deploying outside a maintenance window, device shutdown, account modifications, service changes, scripts not in the approved library. The risk is not that these operations are inherently dangerous — it is that the context that would make them safe is missing.
For High-tier actions, the brain creates an approval request and waits. The request includes the specific action parameters, the brain’s reasoning for why it wants to act, and a structured breakdown of why this action landed in the High tier. The tech can approve as submitted, deny the request, or modify parameters before approving — adjusting the scheduled time, reducing the device scope, or substituting a different patch set.
The approval request structure matters. It is not a generic “approve/deny” prompt. It is a structured object that gives the approver everything needed to make a decision without pivoting to another console.
{
action: "deploy_patches",
device_ids: ["device-123", "device-456"],
params: { patch_ids: ["kb123456"] },
reason: "Critical security patch CVE-2026-1234 (CVSS 9.8). Deploy immediately.",
risk_level: "high",
risk_details: {
outside_maintenance_window: true,
patch_severity: "critical",
device_count: 2
},
approval_link: "https://breezermm.com/approvals/abc123",
expires_at: "2026-02-20T06:00:00Z"
}Approval TTL is configurable, with a default of four hours. If no response arrives before expiry, the request expires. The brain does not retry. It does not resubmit. It does not escalate. If the tech wants the action to proceed, they re-initiate through the brain or execute manually. This is intentional: an AI that retries expired approval requests has misunderstood who is in control.
Critical Risk: Block Entirely, Require Manual Execution
Critical-risk actions are destructive or irreversible at scale: disk wipe, bulk operations above a defined threshold, mass account deletion. The brain cannot execute these. The constraint is not a capability limitation — it is an intentional design decision.
When the brain determines that a Critical-tier action is warranted, it responds with its reasoning and a direct link to the dashboard for manual execution. The human executes manually. The reasoning is preserved. The audit trail records the human decision.
The distinction between “the AI cannot do this” and “the AI is constrained from doing this” matters for how you think about the system. The brain is not incapable of formulating a disk wipe operation. It is prohibited from executing one. That prohibition is enforced by the platform, not by the model.
Context-Awareness: Why the Same Action Has Different Tiers
The four tiers would be simple to implement if every action mapped to a fixed tier. They do not. The tier for a given action is a function of the action parameters, the device state, and the organizational context.
Reboot is the clearest example:
reboot_device:
during maintenance window + single device = Medium
outside maintenance window + single device = High
any time + 50 devices = High (bulk threshold escalation)
any time + 200 devices = CriticalPatch deployment follows a similar pattern, with patch severity as an additional input:
deploy_patch:
severity: Low, within window, device idle = Low
severity: Critical, any time = Medium (urgency overrides window)
severity: any, outside window = High
cross-tenant failure rate > 15% = escalate one tierThe cross-tenant failure rate escalation is worth noting explicitly. If the platform observes that a given patch is failing at a rate above a configurable threshold across multiple organizations, that signal elevates the tier of new deployment requests for that patch. The platform is not just evaluating individual actions — it is evaluating actions in the context of what the fleet data is showing.
The bulk threshold is the other context signal that matters most in practice. Every org has a configurable bulk_threshold (default: 5 devices). Any action that would affect more devices than that threshold escalates one tier. A single-device reboot is Medium. The same reboot targeting 50 devices simultaneously is High. Targeting 200 devices is Critical. This is the protection against the scenario where the AI decides to remediate an entire fleet simultaneously — not because the individual action is dangerous, but because the blast radius of doing it wrong across 200 devices is categorically different from doing it wrong on one.
Why Risk Classification Lives in the RMM, Not the Brain
This is the key architectural decision, and it is worth being explicit about why it was made this way.
The risk classification engine is part of the RMM’s Brain Connector API. Every action request passes through it, regardless of which brain is making the request. Breeze supports BYOK configurations where organizations connect their own model via API key. In those configurations, the brain is external. The risk engine is still internal to the platform. The brain cannot bypass it.
There are four reasons for this.
First, safety must work even when the brain is misbehaving. Prompt injection is a documented attack vector against AI systems. Model errors and runaway loops are operational realities. If risk classification depends on the brain behaving correctly, then the risk classification fails exactly when you need it most. The enforcement layer must be independent of the thing it is enforcing.
Second, MSP admins need to configure risk policy through a UI, not through prompt engineering. Configuring safe behavior by crafting system prompts is fragile — prompts can be overridden, instructions can conflict, and the relationship between prompt text and model behavior is not deterministic. Risk policy is a business configuration that belongs in the database, not in a prompt.
The schema for per-org risk policy overrides reflects this:
riskPolicies table (org-scoped overrides):
- bulk_threshold: integer (default 5)
- maintenance_windows: jsonb [{start: "22:00", end: "06:00", days: ["Mon-Fri"]}]
- approved_script_ids: uuid[] (scripts that can run at Medium risk)
- custom_rules: jsonb [{action: "reboot", condition: "user_active", escalate_to: "high"}]An admin who wants to ensure that reboots never run while a user is active adds a custom rule. They do not edit a system prompt and hope the model respects it.
Third, compliance requires that risk decisions are logged at the platform level. An auditor asking “what controls governed your AI’s autonomous actions last quarter” needs a log produced by the platform, not an inference drawn from model reasoning traces. The risk classification decision — this action was Medium, here is why, here is the timestamp — is a platform-level record.
Fourth, multiple brains might connect to the same RMM. In multi-tenant MSP configurations, different organizations may use different AI providers. Risk policy must be consistent across all of them and enforced by a single layer that all of them pass through.
What This Looks Like in Practice
Across typical MSP environments in testing, roughly 70-75% of brain-initiated actions fall into the Low or Medium tiers — read operations and maintenance-window remediations that execute autonomously. Approximately 20-25% land in High and generate approval requests. Less than 5% reach Critical and require manual execution.
Those numbers mean that the brain handles the majority of operational work without requiring human intervention on each action. The humans who are reviewing approval requests are reviewing the genuinely consequential decisions — the ones where context is missing, where the blast radius is larger than a single device, where the normal window constraints do not apply. They are not reviewing routine diagnostic queries or approving patch deployments that are already scoped within a window the org defined.
The approval workflow is not an obstacle between the AI and execution. It is how the right decisions reach the right people.
Risk Tiers as a Trust-Building Mechanism
There is a second function of this system that is not immediately obvious from the architecture. Risk tiers are not just a safety mechanism — they are the mechanism by which MSPs build trust with the AI over time.
An MSP deploying autonomous AI for the first time has no empirical basis for trusting the brain’s judgment on High-tier decisions. The correct default is conservative policy: a smaller bulk threshold, shorter maintenance windows, a narrower approved script library. The brain operates in a tighter envelope. More of its proposed actions go to approval queues. The MSP reviews those decisions and observes whether the brain’s reasoning is sound.
As that evidence accumulates — as the approval queue shows that the brain consistently recommends appropriate actions with accurate reasoning — the MSP can expand the policy. Increase the bulk threshold. Widen the maintenance windows. Add scripts to the approved library. The risk classification system makes this incremental expansion explicit and configurable rather than requiring the MSP to intuit how much they trust the model based on vague impressions of past performance.
This is not a feature of the AI. It is a feature of the governance layer around it. The AI gets smarter when the model improves. The trust relationship gets stronger when the governance layer makes it possible to observe, evaluate, and expand the envelope based on evidence rather than assumption.
The organizations that get the most value from autonomous AI are the ones that treat trust as something earned through operating history, not granted at deployment.
Breeze’s Brain Connector API and risk classification engine are available to self-hosted deployments and as part of LanternOps, the managed cloud intelligence layer built on Breeze. The next post in this series covers the approval workflow interface — how approval requests surface in existing tools and how the modification flow works in practice.