Build the RMM First. Then Build the Brain.
Here is a failure mode that is becoming common as every RMM vendor rushes to add AI: you ask the assistant why a device’s reliability score dropped, and behind the scenes it runs a script to pull SMART data, calls smartctl, parses the output, reasons over the result, and tells you the drive is showing reallocated sector growth. The demo looks impressive. The architecture is a disaster.
That single query — which felt instantaneous in the demo — cost tokens to gather data the agent should have already collected, burned compute to compute a score that should already exist in your database, and produced a result that will be thrown away the moment the conversation ends. It also means that if the AI is offline, over budget, or rate-limited, you have no drive health data. No dashboard. No alert history. Just a text box that says nothing.
This is what happens when you build the brain first.
The 4-Layer Model
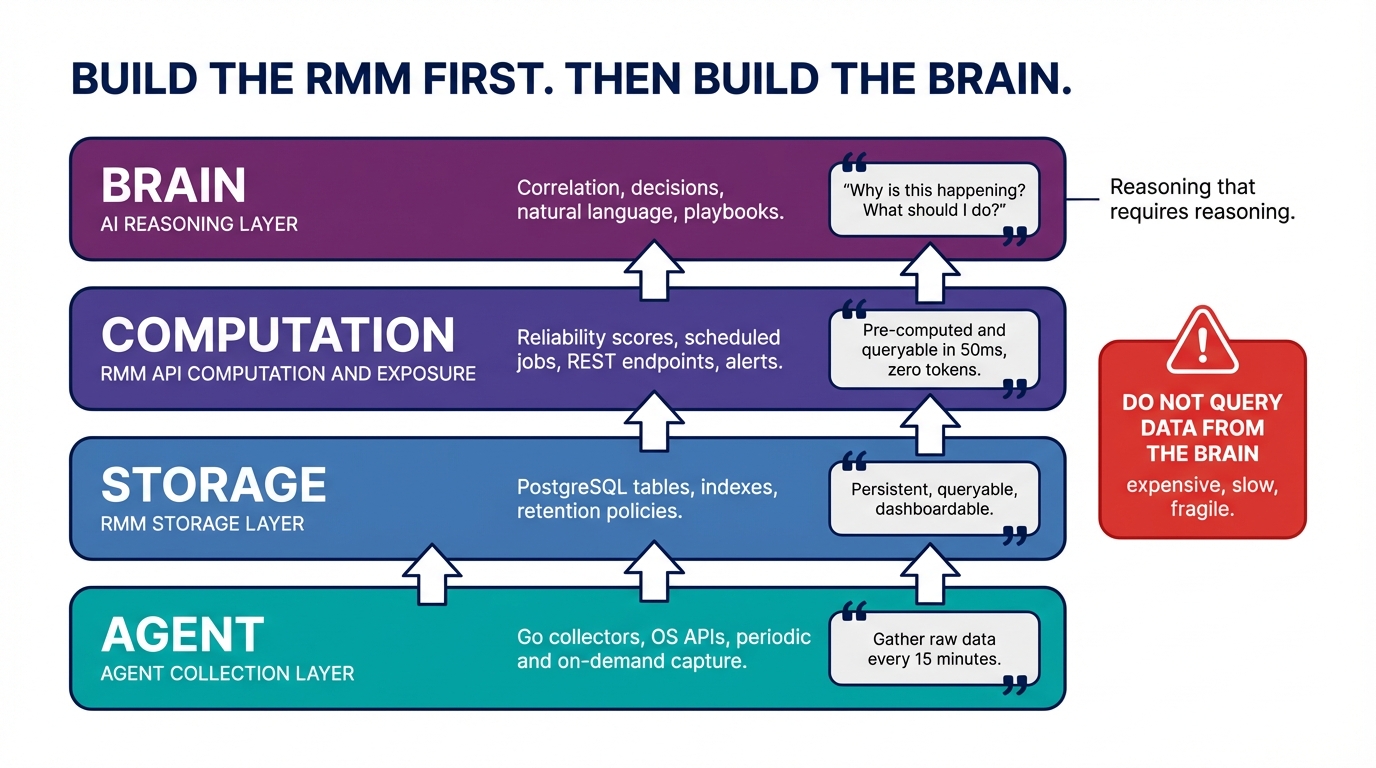
Before writing a line of AI code, it helps to be precise about what each layer of an RMM-plus-AI system is responsible for. The layers are not fuzzy. The boundaries matter.
┌─────────────────────────────────────────────────────┐
│ BRAIN (AI reasoning layer) │
│ Correlation, decisions, natural language, playbooks │
│ "Why is this happening? What should I do?" │
├─────────────────────────────────────────────────────┤
│ RMM API (computation + exposure layer) │
│ Scores, scheduled jobs, REST endpoints, alerts │
│ "Here's the data, pre-computed and queryable" │
├─────────────────────────────────────────────────────┤
│ RMM API (storage layer) │
│ PostgreSQL tables, indexes, retention policies │
├─────────────────────────────────────────────────────┤
│ AGENT (collection layer) │
│ Go collectors, OS APIs, periodic + on-demand │
│ "Gather the raw data" │
└─────────────────────────────────────────────────────┘The agent collects raw data and sends it to the API. The storage layer persists it with appropriate retention policies. The computation layer runs scheduled jobs — BullMQ workers, cron, whatever your stack uses — to produce derived values: reliability scores, patch compliance percentages, SMART health grades. These derived values live in the database. They run in 50 milliseconds with zero tokens. The brain — and only the brain — does the reasoning that genuinely requires reasoning: correlating events across devices, orchestrating multi-step response workflows, answering questions in natural language.
The key discipline is this: every feature that can be implemented below the brain layer should be. The brain is not free. It is not instantaneous. It is not always available. Anything that lives in the brain unnecessarily is expensive, slow, fragile, and invisible to every human who needs to see what is happening without opening a chat interface.
The Anti-Pattern Table
It is easier to understand where this goes wrong when you look at specific examples.
| Bad Pattern | Why It’s Bad | Good Pattern |
|---|---|---|
| Brain computes reliability score every time it’s asked | Costs tokens, slow, inconsistent, no history | Scheduled BullMQ job computes score, brain reads via API |
| Brain runs smartctl via script execution to get SMART data | Expensive, slow, generates command overhead, no trends | Agent collects SMART hourly, brain queries pre-collected data |
| Brain decides what events to log | Core security function shouldn’t depend on AI availability | RMM configures audit baselines deterministically |
| Brain stores compliance state in its own memory | Data lost between sessions, not queryable, not dashboardable | RMM stores in PostgreSQL, brain queries and acts on it |
The SMART data case is the one that tends to produce the most visible sticker shock once people work through the numbers. A platform with 1,000 managed devices that queries SMART data on demand — whether that is triggered by the brain or by a technician asking a question — and spends $0.003 per query in token costs is spending $72 a day just to answer hardware health questions. That figure assumes one query per device per hour, which is modest for an active platform where technicians are routinely asking the assistant about device health. A scheduled Go collector on the agent, writing structured data to a PostgreSQL table once an hour, costs nothing at query time. The data is already there. The brain reads a row.
The compliance state case is subtler but arguably more consequential. If compliance posture lives only in the brain’s conversation memory, it is not queryable. A dashboard cannot display it. A scheduled report cannot include it. An alert cannot fire on it. Another conversation — a new session, a different technician — cannot access it. You have built a compliance system that exists only in a transient context window, and every time the context is lost, the compliance data is lost with it.
What Actually Belongs in the Brain
Avoiding the anti-patterns does not mean the brain has nothing to do. There are categories of features that genuinely require AI reasoning and have no reasonable implementation below the brain layer.
Device Context Memory. The brain’s memory of past conversations with a technician about a specific device — the history of what was asked, what was tried, what was found — has no value without AI reasoning. This is not the same as the device’s metric history, which belongs in PostgreSQL. This is the semantic context of past diagnostic work, and it is only meaningful because the brain can use it to reason about what to try next.
Self-Healing Playbooks. A truly adaptive playbook is not a hard-coded workflow. It is the brain examining a situation, selecting from a set of available tools — tools that call existing API endpoints — and deciding what sequence of actions is appropriate given the specific context. The RMM platform provides the action endpoints. The brain provides the reasoning about which actions to take and in what order. Separating these concerns correctly means the playbooks become more capable as the brain improves, without touching the agent or API code.
End-User Diagnostic Chat. The conversational interface is the brain. There is no meaningful implementation of “help me figure out why my laptop is slow” at the agent or API layer. The brain pulls data from the API, reasons over it in the context of the user’s description, and produces a response. The agent and API are unchanged. The brain is what makes the interaction possible.
Incident Response Orchestration. The decision to isolate a device, collect forensic evidence, disable an account, and notify the client is a reasoning problem. The specific sequence depends on the nature of the incident, the organization’s policies, the devices involved, and the relationships between them. The RMM platform provides the individual action capabilities — network isolation endpoints, evidence collection scripts, account management APIs. The brain drives the workflow by reasoning over the situation. Getting this right requires that the action endpoints exist and work correctly before you write the orchestration logic.
The Build Sequence
There is a correct order to build this, and it is not negotiable if you want a system that is both capable and reliable.
Phase 1: Agent collectors + DB tables + API endpoints
(RMM works standalone, dashboards show real data)
|
Phase 2: Brain tool wrappers
(Each API endpoint gets a tool definition — trivial once Phase 1 exists)
|
Phase 3: Brain patterns
(Playbooks, correlation, IR orchestration — pure brain logic)
|
Phase 4: BYOK integration
(Local brain calls local API — validate everything works)
|
Phase 5: Remote brain
(Add brain auth layer, same tools work remotely via HTTP)Phase 1 is the expensive one. It requires Go agent development for each data type you want to collect. It requires schema design that accounts for retention, indexing, and query patterns you have not fully defined yet. It requires API endpoint design that is useful to humans — dashboards, reports, direct REST access — before you have any AI tooling at all. This phase takes longer than a demo-first approach. It requires architectural discipline. And it produces something that feels, for a while, like it has nothing to do with AI.
That is the point. Phase 1 produces an RMM that works without the brain. Dashboards display real data. Alerts fire deterministically. Scheduled jobs run and produce stored results. Technicians can do their work using the platform directly. This is not a prototype or a placeholder. It is the foundation that makes everything else reliable.
Phase 2 is where the payoff starts to become visible. Once the API endpoints exist, wrapping them as tool definitions for an LLM is mechanical work. The tool definitions describe what the endpoint does, what parameters it accepts, and what it returns. The brain can call them immediately. The tools are grounded in real data because the data was collected in Phase 1. There is no hallucination risk on factual queries — the brain calls the tool, gets the data, and reasons over it.
Phase 5 deserves specific attention because it tends to surprise people with how little work it involves once Phases 1 through 4 are solid. The tool definitions in a local brain deployment and a remote deployment are identical. The only thing that changes is the network path: instead of local function calls, the tool functions make authenticated HTTP calls to the RMM API. The brain does not know or care. The tool abstractions that worked locally work remotely without modification. If you built the stack correctly, adding a remote brain layer is an authentication and routing problem, not an architecture problem.
The Honest Tradeoff
There is a version of this post that sells you on the 4-layer model by making it sound inevitable. It is not. There are real costs to building the platform first.
The primary cost is time-to-demo. A system that computes SMART health data on demand in an AI chat interface can be built in a week. A system where a Go agent collects SMART data hourly, writes it to a PostgreSQL table with appropriate indexes and retention policies, exposes it via a REST endpoint with query parameter support for time ranges and device filtering, runs a scheduled job that computes aggregate health scores, and then wraps all of that in tool definitions for an LLM — that takes considerably longer. There is nothing to show until all of the layers exist.
The secondary cost is discipline. Every feature request that comes in will have a path of least resistance: put it in the brain, ship it in a day, move on. The discipline required to say “no, this belongs in the agent and the API” — and to do that work before writing the AI code — is genuinely hard to maintain under schedule pressure.
But the costs of inverting the model are not recoverable. Token spend scales with device count and query frequency. Historical data that was never collected cannot be backfilled. Dashboards built on AI-computed values break when the AI is unavailable. Compliance data stored in conversation memory is lost when the context ends. These are not bugs you can fix with a hotfix. They are architectural debts that compound until the system becomes unmanageable.
The RMM has to exist as a real platform before the brain is added. Not as a shell. Not as a thin data layer designed only to serve the AI. As a system that a technician would use with or without the AI available — one that stores history, fires alerts, runs scheduled jobs, and serves dashboards. That foundation is what makes the brain trustworthy, the tool calls reliable, and the architecture sound enough to scale beyond a demo.
Breeze is built on this model. The agent collectors, schema design, API endpoints, and scheduled scoring jobs are the platform. LanternOps is the brain that runs on top of it. Every AI-powered capability in LanternOps calls a real API endpoint backed by real collected data — because that is the only way to make AI-powered infrastructure management something you can actually operate at scale.