The Brain Connector Pattern: One Tool Schema, Two Execution Contexts
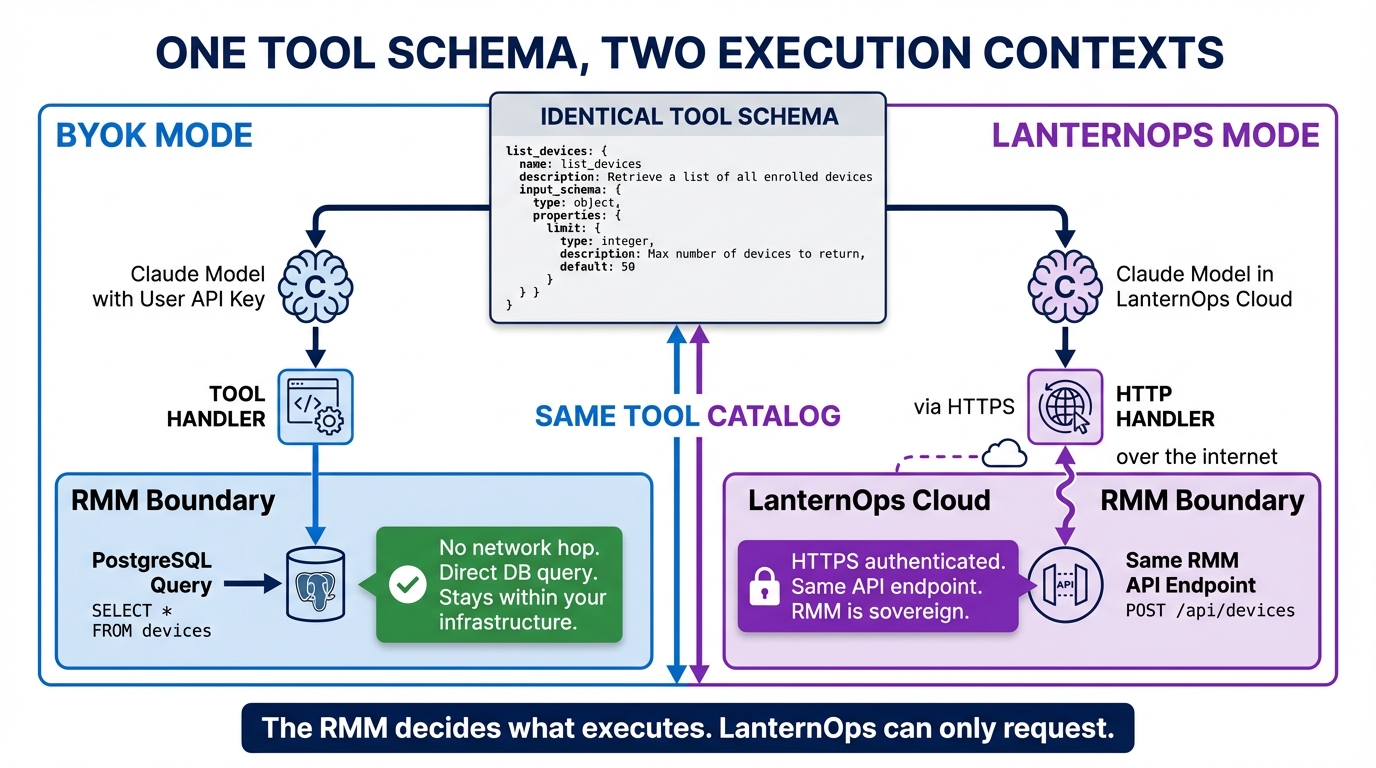
The Agent SDK does not know where a tool’s handler runs. It sees a function signature and a JSON Schema. Whether that function makes a direct database query or an HTTPS request to a remote API on the other side of the internet is completely invisible to the agent. That property — the execution context opacity of tool definitions — is the key insight that makes the brain connector pattern possible, and it has significant architectural implications if you are building anything in this space.
This post is about how we use that property to let the same tool schemas run in two fundamentally different execution contexts: BYOK mode, where the agent and its tools run locally inside the open source RMM, and LanternOps mode, where the agent runs in our cloud and the tools are thin HTTP wrappers around the same RMM endpoints the BYOK agent calls directly. The tool catalog is identical. The brain behavior is identical. What changes is only the wiring underneath.
What “Identical Tool Schemas” Actually Means
Before getting into the architecture, it is worth being precise about what “identical” means in this context.
The Agent SDK’s contract with a tool is its name, description, and input schema. The description tells the model when to use the tool. The input schema tells it what arguments to pass. Neither the description nor the schema contains anything about how the handler executes. That implementation detail lives entirely outside the contract.
Here is what the list_devices tool definition looks like in Breeze:
// This tool definition is identical in BYOK mode and LanternOps mode.
// What changes is what _handler points to — not this object.
const listDevicesTool = {
name: "list_devices",
description: "List managed devices with optional filters. Returns device ID, hostname, OS, last seen, health status, and compliance state.",
input_schema: {
type: "object",
properties: {
tenant_id: { type: "string" },
filters: {
type: "object",
properties: {
os: { type: "string" },
health_status: { type: "string", enum: ["healthy", "warning", "critical"] },
compliance_score_below: { type: "number" }
}
},
include_details: {
type: "array",
items: { type: "string", enum: ["hardware", "software", "network", "security"] }
}
},
required: ["tenant_id"]
}
}That object ships with the open source RMM. It is published, versioned, and stable. What the BYOK setup and LanternOps do with it — specifically, what they wire _handler to — is where the two modes diverge.
BYOK Mode: Local All the Way Down
In BYOK mode, the entire agent loop runs inside the MSP’s own infrastructure. The MSP provides their Anthropic API key. The agent runs as a local process inside the RMM. When the agent decides to call list_devices, the handler executes a direct database query — no network hop, no remote call, just a PostgreSQL query against the same database everything else in the RMM reads from.
┌─ Open Source RMM (Local) ──────────────────────────────┐
│ │
│ BYOK Agent Loop │
│ ┌─────────────────────────────────┐ │
│ │ Claude (user's API key) │ │
│ │ "I should check device status" │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ calls list_devices() tool │ │
│ └────────┬────────────────────────┘ │
│ │ │
│ ▼ │
│ Tool handler: list_devices_local() │
│ ┌─────────────────────────────────┐ │
│ │ // NOT an HTTP call │ │
│ │ // Direct DB query │ │
│ │ db.query(Device) │ │
│ │ .filter_by(tenant_id=...) │ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘The same pattern applies to actions. When the BYOK agent calls execute_action, the handler runs the risk classifier locally, applies the MSP’s custom risk rules against the local database, and either blocks, queues for approval, or executes — all within the same process boundary as the RMM itself. The audit trail writes to the same PostgreSQL instance. The approval workflow surfaces in the same UI technicians are already using.
This is a complete, production-capable AI operations setup. The MSP pays Anthropic directly for API usage. Nothing leaves their infrastructure except the token stream to Anthropic’s API. It works well for reactive triage and single-tenant use cases.
LanternOps Mode: Same Endpoints, Different Call Site
In LanternOps mode, the agent runs in our cloud. The tools are HTTP wrappers around the same Brain Connector API endpoints that the BYOK agent calls through its local handlers.
┌─ LanternOps Cloud ──────────────────────────────────────┐
│ │
│ Agent SDK (Claude Sonnet) │
│ "I should check device status" │
│ calls list_devices() tool │
│ │ │
│ ▼ │
│ Tool handler: list_devices_remote() │
│ // Identical schema, different wiring │
│ await rmm_client.call("/devices/list", {...}) │
│ │ │
└────────────┼─────────────────────────────────────────────┘
│ HTTPS (authenticated, encrypted)
│
┌────────────▼─────────────────────────────────────────────┐
│ Open Source RMM (Customer's Infrastructure) │
│ Brain Connector API │
│ /api/v1/devices/list │
│ (same endpoint BYOK calls locally) │
└───────────────────────────────────────────────────────────┘The agent code behavior is the same. The tool schemas are the same. The Brain Connector endpoints are the same — the RMM doesn’t care whether the call arrived over a local function invocation or an HTTPS request from our cloud. It validates credentials, checks tenant access, enforces risk classification, and responds. The call site moved from inside the process to outside the network perimeter. Everything inside the RMM’s trust boundary remained unchanged.
This is the key property: the RMM is sovereign. LanternOps can request. The RMM decides what executes.
The Double Risk Validation Layer
One of the properties this architecture enables is belt-and-suspenders risk enforcement. Both execution contexts enforce risk classification, but at different levels with different information.
The RMM’s risk engine classifies every action based on action type, target devices, time of day, custom rules the MSP administrator has configured, and historical device context. A script deployment to 200 devices during business hours looks different to the risk engine than the same deployment to an isolated test group at 2 AM. This classification happens regardless of who is calling — BYOK agent, LanternOps, or a human in the UI. It is a property of the action, not the caller.
LanternOps adds a pre-validation pass before the request reaches the RMM at all. This pre-validation draws on information the individual RMM instance does not have access to:
Cross-tenant signals: if three other MSPs’ tenants have reported failures or BSODs after applying a specific patch in the last 24 hours, LanternOps can surface that signal before the action is submitted, even though the individual RMM has no visibility into those other tenants. The data is anonymized and aggregated, but the pattern is real.
Tenant-specific history: LanternOps maintains a persistent memory of past incidents, resolutions, and device quirks across sessions. If this script caused a problem on a device with a similar hardware profile last week, that context is available at pre-validation time even if the RMM’s event history has aged out.
Timing analysis: usage pattern data for an organization can identify that a planned reboot hitting at 2 PM on a Tuesday falls in the middle of that tenant’s heaviest work period. LanternOps can flag this and suggest deferring to a low-usage window.
When LanternOps pre-validation raises a concern, the request can be blocked or modified before it ever reaches the RMM’s risk engine. When LanternOps pre-validation passes, the RMM’s risk engine still runs independently — it does not inherit or trust LanternOps’s clearance. Both checks must pass for an action to execute. An action that LanternOps approves can still be blocked by the RMM’s risk classifier. An action that the RMM’s classifier would approve can be stopped by LanternOps before it arrives.
Neither layer knows the other exists. The RMM doesn’t know whether LanternOps ran a pre-validation pass. LanternOps doesn’t know how the RMM’s risk classifier will evaluate the request. That independence is what makes the double-layer meaningful.
LanternOps-Only Tools
There is a category of tools that exist only in LanternOps mode and are intentionally absent from BYOK. These are not capabilities that were excluded from BYOK for business reasons — they require infrastructure that does not exist in a single-tenant local deployment.
query_memory searches LanternOps’s vector store for past incidents, resolutions, device quirks, and operational patterns for a specific tenant. It works across sessions: what was observed and resolved three months ago is available in the current session. BYOK has no equivalent because each agent loop starts fresh — there is no external memory store in a BYOK deployment.
check_cross_tenant queries aggregated, anonymized pattern data from across LanternOps’s tenant base. Has this patch caused failures elsewhere? Has this script pattern been associated with negative outcomes on similar device profiles? Has this alert signature been seen before, and if so, what resolved it? The data required for this tool spans every MSP tenant in LanternOps. BYOK cannot have it by definition.
invoke_playbook executes validated operational playbooks — structured sequences of actions that have been tested, reviewed, and encoded in LanternOps’s playbook library. Playbooks encode operational knowledge that accumulates over time across all LanternOps users. They don’t exist in BYOK because there is no shared library to maintain and serve them from.
These tools are the honest answer to the question of what LanternOps provides that BYOK does not. It is not a better agent. It is not a smarter model. It is persistent memory, cross-tenant intelligence, and a validated playbook library — and those three things require cloud infrastructure that a local BYOK deployment cannot replicate.
The Tool Catalog as API Contract
The most underappreciated part of this architecture is the versioning problem.
The tool catalog is the API contract between the brain and the RMM. Breaking changes to tool schemas are breaking changes to every brain consuming them. This is not a theoretical concern — the Agent SDK is sending the tool names and input schemas directly to the model as part of its context, and the model is generating tool calls based on what it sees. If a field is renamed, a required parameter is added, or an enum value changes, every brain that has internalized the old schema through its conversation context will generate invalid tool calls against the new schema.
We treat tool schemas with the same versioning discipline as public APIs.
Breaking changes require a new tool name. If list_devices needs a parameter change that removes backward compatibility, the new version is list_devices_v2. The old tool remains available. Both are present in the catalog simultaneously during the transition period.
Non-breaking changes — adding optional parameters, extending enum values, adding fields to responses — are applied in place without a version increment. The model does not need to know about optional parameters it does not use, and additional response fields do not break consumers that ignore unknown fields.
Backward compatibility is maintained for at least one major version after deprecation. Deprecated tools are flagged in the catalog with a deprecated_since field and a migration pointer. LanternOps uses the catalog’s version metadata to detect when a connected RMM instance is running a schema that is out of date and can surface that as a compatibility warning before tool failures occur.
The registration handshake enforces this. When a brain connects — whether BYOK or LanternOps — the first thing it does is call /brain/register, which returns the current tool catalog with full schema definitions and version metadata. The brain uses that catalog to wire its tools. If the RMM ships a new tool version, the next registration returns an updated catalog, and the brain rewires accordingly. No manual coordination required.
Most teams building in this space skip the versioning infrastructure. They discover the need for it the first time they have to change a tool schema that a deployed brain is actively using. At that point, the options are bad: break existing deployments silently, maintain two incompatible codepaths with no coordination mechanism, or take downtime to force synchronization. Building the versioning contract from the start costs a small amount of upfront structure. Not building it costs a production incident.
The Upgrade Path Is Zero Migration
The clean upgrade story matters enough to describe precisely.
An MSP installs the open source RMM and configures BYOK with their Anthropic API key. The agent runs locally, calls local handlers, and handles reactive triage well. There is no persistent memory between events — each alert starts a fresh context window. There is no cross-tenant intelligence — the agent knows only what this RMM instance has seen. There are no playbooks — the agent reasons from scratch each time.
When the MSP connects LanternOps, the following things happen: LanternOps calls /brain/register against the MSP’s RMM and receives the current tool catalog. LanternOps instantiates a cloud agent wired to HTTP handlers that call that RMM’s Brain Connector endpoints. LanternOps begins consuming the RMM’s event stream via WebSocket and starts building its tenant memory from events as they arrive.
Nothing else changes. The RMM’s data, the device agents, the alert configurations, the risk policy, the UI — all of it is the same. The MSP does not migrate data. They do not redefine tools. They do not change the endpoints the brain calls, because LanternOps is calling the same endpoints the BYOK agent called through its local handlers.
What they gain immediately: query_memory over everything LanternOps observes going forward, check_cross_tenant against the full LanternOps tenant base, and invoke_playbook against the playbook library. What they no longer pay: Anthropic API costs directly — those are absorbed into the LanternOps subscription.
The zero-migration property is not a marketing claim. It is a direct consequence of the tool schemas being the API contract and the Brain Connector endpoints being the implementation shared between both modes.
What This Means for Architects Building in This Space
If you are building an AI-augmented operations platform, the decision you make about tool definition ownership determines how much flexibility you have later.
If tool schemas live in the brain and the RMM is a passive data source, you cannot offer a BYOK mode without reimplementing the schemas locally. You cannot guarantee that local and cloud executions are behaviorally identical. You cannot independently version the contract. The brain and the data layer are coupled by something other than a published interface.
If tool schemas live in the RMM and are published as a versioned catalog — if the RMM is sovereign and the brain is just a well-behaved client of a stable API — then the execution context becomes a deployment decision, not an architectural constraint. You can run local. You can run in cloud. You can run both simultaneously. You can upgrade either side independently as long as the catalog contract is respected.
The Agent SDK’s execution context opacity makes this possible. It does not enforce it. The discipline of treating the tool catalog as a first-class, versioned, published contract is what turns a property of the SDK into an architectural guarantee.
Next in Track 3: The Risk Enforcement Layer — how the four-tier action classifier works and why it is enforced at the RMM rather than the brain.
For the operational picture of what BYOK and LanternOps mean for your day-to-day: Configuring Breeze AI: The Self-Hoster’s Guide — the Track 1 breakdown of what each mode requires to run in practice.